

计算机处理中文信息的基础是汉字代码查询,它一般是借助汉字的特定编码,像区位码、机内码,或者输入法码来反向找出对应汉字的过程,这项操作在早期中文信息处理、古籍数字化以及某些特定工业控制场景当中依旧存在实际应用 。

开始查询之前,要先弄清楚所运用的编码标准,较为常用的是国标码,也就是GB2312及其扩展的版本,该版本的区位码能够经由计算或者查阅码表来获取,比如说,“啊”这个字的区位码是1601,相对应的机内码是B0A1,在程序设计期间,可以借助标准库函数达成编码与字符之间的相互转换。
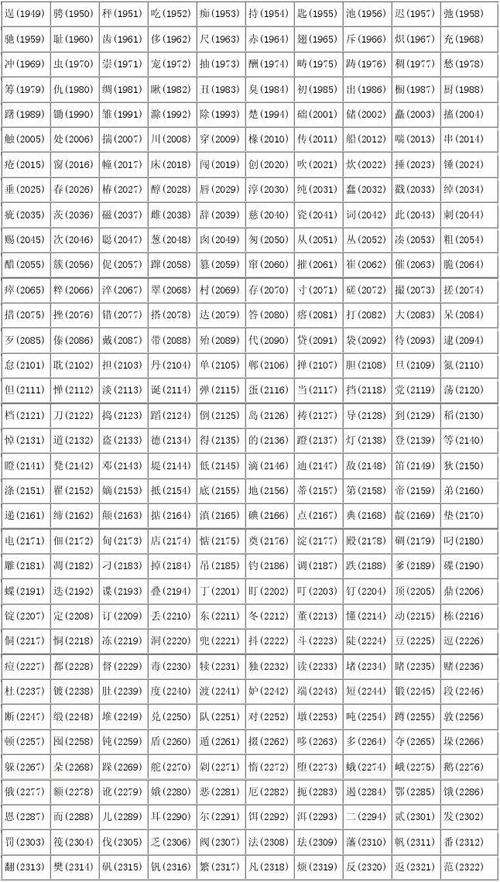
这种底层查询,对多数普通用户而言,虽已没必要,然而在解决乱码问题时,它是关键技能,在兼容老旧系统期间,它是关键的技能,进行字符集研究之际,它也是关键的技能。开发者有可能需要核查字符是不是在特定字符集里面,或者处理来自不同年代数据源的信息 。

你有没有在工作期间遭遇因字符编码紊乱致使的问题?又或者对某个冷僻字的编码存有好奇之感?非常欢迎来到评论区之中把你的经历或者疑问分享出来。